
Poznaj zaawansowane techniki ekstrakcji tabel z PDF do Excela. Dowiedz się, jak AI rozwiązuje problem 'łamanych' wierszy i automatycznie konwertuje dane bez błędów formatowania.
Każdy, kto kiedykolwiek próbował ręcznie przenieść dane z dokumentu PDF do Excela, wie, jak frustrujący może być problem z formatowaniem tabel w PDF. 'Łamane' wiersze, rozdzielone nagłówki, scalone komórki – to codzienność przy tradycyjnej konwersji pdf do excel. W tym kompleksowym przewodniku pokażemy, jak zaawansowana technologia AI rewolucjonizuje proces ekstrakcji tabel z pdf, eliminując błędy i automatyzując żmudną pracę manualną.
Dlaczego tradycyjne metody zawodzą przy ekstrakcji line items?
Klasyczne podejścia do ekstrakcji tabel z pdf opierają się często na prostym kopiowaniu i wklejaniu lub podstawowych narzędziach OCR. Problem polega na tym, że dokumenty PDF nie są stworzone do łatwej ekstrakcji danych – to format prezentacyjny, a nie strukturalny. Kiedy próbujesz jak skopiować tabelę z pdf do excela metodą 'copy-paste', napotykasz szereg wyzwań:
Najczęstsze problemy przy ręcznej konwersji
1. Łamanie wierszy: Długie teksty automatycznie przechodzą do następnej linii, tworząc pozornie nowe wiersze w Excelu
2. Rozdzielone nagłówki: Tytuły kolumn rozbite na kilka komórek
3. Scalone komórki: Informacje z wielu kolumn w jednej komórce PDF
4. Brak struktury: PDF nie przechowuje informacji o tabelach w sposób strukturalny
Te problemy sprawiają, że ręczna konwersja pdf do excel zajmuje godziny i jest podatna na błędy. W przypadku dokumentów takich jak faktury, gdzie precyzja jest kluczowa, każdy błąd w sczytywaniu pozycji z faktury może mieć poważne konsekwencje finansowe.
Jak działa zaawansowana ekstrakcja tabel z AI?
Nowoczesne rozwiązania do line items extraction wykorzystują sztuczną inteligencję do zrozumienia struktury dokumentu. Zamiast prostego rozpoznawania tekstu (OCR), systemy AI analizują kontekst, relacje przestrzenne między elementami i semantykę dokumentu. W PARSEMINT wykorzystujemy zaawansowane algorytmy Deepseek AI, które potrafią:
Kluczowe możliwości AI w ekstrakcji tabel
• Rozpoznawanie struktury tabel nawet w skomplikowanych układach
• Automatyczne łączenie 'łamanych' wierszy w logiczne rekordy
• Identyfikacja nagłówków i danych na podstawie kontekstu
• Obsługa tabel wielostronicowych z zachowaniem ciągłości danych
• Rozróżnianie tabel od pozostałej treści dokumentu
Dzięki temu rozwiązaniu problemu z formatowaniem tabel w PDF staje się prosty i automatyczny. Jak opisaliśmy w naszym wcześniejszym artykule o różnicach między regex a AI w analizie dokumentów, tradycyjne metody po prostu nie radzą sobie ze zmiennymi układami dokumentów.
Krok po kroku: jak skopiować tabelę z PDF do Excela bez błędów
Pokażemy Ci praktyczny proces bezbłędnej konwersji pdf do excel przy użyciu zaawansowanych narzędzi AI. Ten proces eliminuje większość problemów związanych z ręcznym przetwarzaniem danych.
Etap 1: Przygotowanie i analiza dokumentu
Pierwszym krokiem jest załadowanie dokumentu do systemu. W przypadku PARSEMINT obsługujemy pliki do 100MB (w zależności od planu), co pozwala na przetwarzanie nawet bardzo obszernych raportów. System automatycznie wykrywa wszystkie tabele w dokumencie i analizuje ich strukturę. To kluczowy moment dla poprawnego sczytywania pozycji z faktury czy innych dokumentów finansowych.
Etap 2: Automatyczna ekstrakcja i walidacja
AI przystępuje do ekstrakcji danych, łącząc 'łamane' wiersze i rozpoznając relacje między komórkami. System wykorzystuje kontekst – na przykład, jeśli w kolumnie są kwoty, automatycznie formatuje je jako liczby. W przypadku wątpliwości, system może oznaczyć dane do weryfikacji, co jest szczególnie ważne przy ekstrakcji tabel z pdf zawierających krytyczne dane finansowe.
Zaawansowane techniki OCR tabel dla skomplikowanych dokumentów
Nie wszystkie dokumenty są stworzone jednakowo. Szczególnie wymagające są skany dokumentów, ręcznie wypełniane formularze czy tabele z niestandardowym formatowaniem. W takich przypadkach tradycyjny ocr tabel może nie wystarczyć.
Rozwiązania dla trudnych przypadków
• Tabele z obróconym tekstem: AI potrafi rozpoznać i skorygować obrót tekstu
• Dokumenty z niską rozdzielczością: zaawansowane algorytmy poprawy jakości obrazu
• Formularze z polami do zaznaczenia: rozpoznawanie znaczników i checkboxów
• Tabele z nieregularną siatką: analiza relacji przestrzennych zamiast sztywnej siatki
Te zaawansowane możliwości sprawiają, że nawet najbardziej skomplikowane dokumenty mogą być przetworzone automatycznie. W naszym artykule o automatyzacji analizy finansowej PDF pokazaliśmy, jak te techniki działają w praktyce w środowisku korporacyjnym.
API do parsowania tabel: automatyzacja na skalę przedsiębiorstwa
Dla organizacji przetwarzających setki lub tysiące dokumentów miesięcznie, ręczna konwersja pdf do excel jest po prostu nieopłacalna. Tutaj z pomocą przychodzi api do parsowania tabel, które pozwala zintegrować ekstrakcję danych z istniejącymi systemami.
Kluczowe korzyści API do ekstrakcji tabel
1. Pełna automatyzacja: Integracja z systemami ERP, CRM i bazami danych
2. Przetwarzanie wsadowe: Jednoczesna analiza setek dokumentów
3. Niestandardowe workflow: Dostosowanie procesu do specyficznych potrzeb biznesowych
4. Monitorowanie w czasie rzeczywistym: Śledzenie statusu przetwarzania dokumentów
W PARSEMINT oferujemy zaawansowane api do parsowania tabel w planach Professional i Enterprise. Jak opisaliśmy w dedykowanym artykule o pełnej automatyzacji dokumentów PDF, odpowiednia integracja może zredukować czas przetwarzania dokumentów nawet o 95%.
Narzędzie do konwersji PDF na JSON: dlaczego to przyszłość ekstrakcji danych?
Chociaż Excel jest powszechnie używanym formatem, coraz więcej aplikacji i systemów preferuje dane strukturalne w formacie JSON. Narzędzie do konwersji pdf na json oferuje dodatkowe korzyści, szczególnie dla developerów i zaawansowanych integracji.
Przewagi JSON nad tradycyjnymi formatami
• Struktura hierarchiczna: Lepsze odwzorowanie złożonych relacji w danych
• Łatwa integracja z aplikacjami webowymi: Natywna obsługa w nowoczesnych frameworkach
• Mniejszy rozmiar plików: Optymalizacja przesyłania i przechowywania danych
• Semantyczne znaczniki: Dodatkowe metadane o strukturze i znaczeniu danych
W dokumentacji API PARSEMINT znajdziesz szczegółowe informacje o tym, jak wykorzystać narzędzie do konwersji pdf na json w swoich projektach. To szczególnie przydatne przy budowaniu zautomatyzowanych pipeline'ów danych, gdzie informacje z dokumentów PDF muszą być natychmiast dostępne dla innych systemów.
Case study: automatyzacja sczytywania pozycji z faktury w korporacji
Pokażemy realny przykład z korporacji z branży produkcyjnej, która przetwarzała ponad 5000 faktur miesięcznie. Przed wdrożeniem automatyzacji, sczytywanie pozycji z faktury zajmowało średnio 15 minut na dokument i było obarczone 8% błędów.
Wyniki po wdrożeniu AI do ekstrakcji tabel
• Czas przetwarzania: Zmniejszony z 15 do 0,5 minuty na fakturę
• Dokładność: Wzrost z 92% do 99,7%
• Koszty operacyjne: Redukcja o 75% w dziale księgowości
• Skalowalność: Możliwość przetwarzania 3x większej liczby dokumentów bez dodatkowych zasobów
Ten przykład pokazuje, jak zaawansowana ekstrakcja tabel z pdf może przełożyć się na realne korzyści biznesowe. Podobne case study znajdziesz w naszym artykule o automatycznym obiegu faktur z ParseMint i Zapier.
PDF to CSV converter: kiedy warto wybrać CSV zamiast Excela?
Chociaż Excel jest popularny, format CSV ma swoje unikalne zalety w określonych scenariuszach użycia. Pdf to csv converter jest szczególnie przydatny w następujących sytuacjach:
Optymalne zastosowania formatu CSV
1. Import do baz danych: CSV jest standardowym formatem importu/eksportu
2. Przetwarzanie dużych zbiorów danych: Lżejszy format niż pliki Excel
3. Integracja z systemami Linux: Brak zależności od bibliotek Microsoft
4. Przechowywanie wersji w Git: Łatwe śledzenie zmian w danych
Warto zauważyć, że dobre narzędzie do konwersji pdf na json często oferuje również eksport do CSV, dając użytkownikom elastyczność wyboru formatu najbardziej odpowiedniego dla ich potrzeb. W funkcjach PARSEMINT oferujemy zarówno eksport do Excel, jak i CSV, a także bezpośrednią integrację z bazami danych przez API.
Best practices: jak przygotować dokumenty PDF do optymalnej ekstrakcji
Nawet najlepsze narzędzia do line items extraction działają lepiej z dobrze przygotowanymi dokumentami. Oto praktyczne wskazówki, jak przygotować swoje PDF-y do bezbłędnej konwersji.
Złote zasady przygotowania dokumentów
• Wybieraj dokumenty tekstowe zamiast skanów: Jeśli masz wybór
• Unikaj nadmiernego formatowania: Proste tabele są łatwiejsze do przetworzenia
• Zachowaj spójne nagłówki: Ułatwia to identyfikację kolumn
• Testuj z reprezentatywnymi próbkami: Przed przetworzeniem całego zbioru
• Korzystaj z szablonów: Tam gdzie to możliwe
Te praktyki znacząco poprawiają skuteczność ocr tabel i redukują potrzebę ręcznej korekty. Więcej o optymalizacji dokumentów dla AI przeczytasz w naszym artykule o systemie szybkich przetargów z automatyczną ekstrakcją danych.
Przyszłość ekstrakcji tabel: trendy i rozwój technologii
Technologie ekstrakcji danych z dokumentów PDF rozwijają się w zawrotnym tempie. Oto najważniejsze trendy, które kształtują przyszłość ekstrakcji tabel z pdf:
Kluczowe kierunki rozwoju
1. AI kontekstowe: Systemy rozumiejące znaczenie danych w szerszym kontekście
2. Przetwarzanie multimodalne: Łączenie analizy tekstu, obrazów i struktur
3. Automatyczne uczenie: Systemy dostosowujące się do specyficznych formatów dokumentów
4. Integracja blockchain: Weryfikacja autentyczności i pochodzenia danych
5. Real-time processing: Natychmiastowa ekstrakcja danych z dokumentów streamingowych
Te rozwinięcia sprawią, że problemy z formatowaniem tabel w PDF staną się przeszłością, a proces konwersji pdf do excel będzie w pełni zautomatyzowany i bezbłędny.
Podsumowanie: dlaczego warto automatyzować ekstrakcję line items?
Ekstrakcja tabel z dokumentów PDF to nie tylko kwestia wygody – to strategiczna decyzja biznesowa. Automatyzacja procesu jak skopiować tabelę z pdf do excela przynosi wymierne korzyści:
• Oszczędność czasu: Redukcja czasu przetwarzania nawet o 95%
• Wyższa dokładność: Eliminacja błędów ludzkich przy ręcznym wprowadzaniu
• Skalowalność: Możliwość przetwarzania dowolnej liczby dokumentów
• Lepsze wykorzystanie zasobów: Pracownicy mogą skupić się na analizie, a nie wprowadzaniu danych
• Szybsze podejmowanie decyzji: Dane dostępne natychmiast po otrzymaniu dokumentów
Jeśli zmagasz się z problemami przy sczytywaniu pozycji z faktury lub innych dokumentów, warto rozważyć wdrożenie zaawansowanego rozwiązania do ekstrakcji tabel. W PARSEMINT oferujemy różne plany subskrypcji dostosowane do potrzeb indywidualnych użytkowników, małych firm i dużych przedsiębiorstw. Zacznij od darmowego planu, który pozwala na przetestowanie 3 dokumentów miesięcznie, i przekonaj się, jak AI może zrewolucjonizować Twoją pracę z dokumentami PDF.
Pamiętaj, że w dzisiejszym świecie danych, szybkość i dokładność ekstrakcji informacji mogą być kluczową przewagą konkurencyjną. Nie pozwól, aby problem z formatowaniem tabel w PDF spowalniał rozwój Twojej organizacji.
Wypróbuj PARSEMINT już dziś!
Rozpocznij analizę dokumentów PDF z pomocą sztucznej inteligencji. Bezpłatny plan dostępny od razu.
Powiązane wpisy

Archiwum "Przed KSeF": Jak zdigitalizować segregatory z lat 2020-2025 w jeden weekend?
Praktyczny przewodnik po masowej cyfryzacji archiwum dokumentów sprzed KSeF. Dowiedz się, jak przenieść stare faktury do chmury i stworzyć przeszukiwalne PDF w 48 godzin.
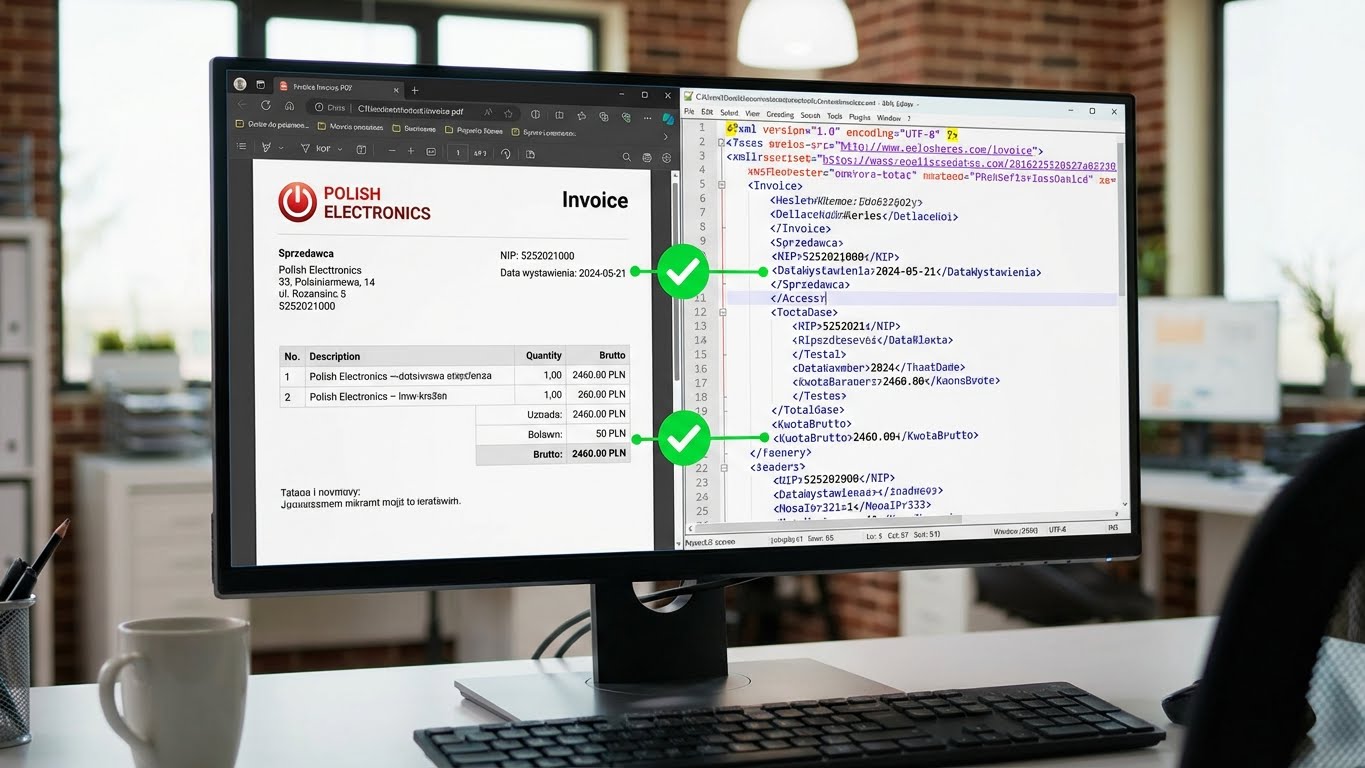
Walidacja KSeF: Jak automatycznie sprawdzić zgodność PDF (Wizualizacja) z XML?
Poznaj metody automatycznej weryfikacji faktur KSeF. Dowiedz się, jak sprawdzić zgodność PDF z XML i uniknąć błędów księgowych dzięki inteligentnej analizie dokumentów.

Dziura w KSeF: Paragony, Taksówki i Delegacje. Jak domknąć cyfryzację wydatków pracowniczych?
Poznaj praktyczne rozwiązania na domknięcie obiegu dokumentów w KSeF. Dowiedz się, jak rozliczać paragony, bilety autostradowe i faktury uproszczone w spójnym systemie księgowym.